
Google DeepMind recently released Gemma 4 12B, a dense multimodal model that completely strips traditional encoders. Vision and sound flow straight to the core of the LLM. The result is a model that runs an agent workflow on a consumer laptop with 16 GB of RAM. It is distributed under the Apache 2.0 license.
Model overview and access
The Gemma 4 12B is a 12-billion-parameter decoder-only transformer. It handles text, images, audio, and video natively. There are no separate optical or audio encoders. The decoder uses the same architecture as the Gemma 4 31B Dense model. It bridges the gap between the edge-friendly E4B and the extreme variation of the 26B Mixture of Experts.
- Architecture: Integrated transformer, no encoder only.
- Methods: Text, image, video, and native audio input — the first mid-sized Gemma with audio.
- Hardware requirement: 16 GB VRAM or integrated memory. Works on consumer GPU laptops and Apple Silicon Macs.
- License: Apache 2.0. Weights are open and publicly available.
- A stack of considerations: Compatible with llama.cpp, MLX, vLLM, Ollama, SGlang, Unsloth, and LM Studio.
- Download: Face Hugs and Kaggle. The teaching difference is
google/gemma-4-12B-it. - Integration: Hugging Face Transformers, LiteRT-LM CLI, and local API server compatible with OpenAI via
litert-lm serve.
A dedicated Multi-Token Prediction (MTP) draft model is also released. Reduce inference latency on local hardware.
Features: Encoderless Design
All previous mid-size Gemma models used separate Transformer amplifiers for audio and video. Those encoders added more delay and parameter. The mid-sized Gemma 4 models carry a 550M optical encoder. The E2B and E4B models feature a 300M parameter audio encoder. All of that is over in 12B.
Embedded view (35M parameters): Raw images are divided into 48×48 pixels. Each slice is expressed in the hidden dimensions of the LLM by one iteration of the matrix. There is no layer of attention; each episode is analyzed independently. The location is injected using a factorized coordinate lookup: the read X matrix and the read Y matrix. To find a patch at (x, y), the model looks at the two learned embeddings and adds them to form a location vector. This is added to the embedding of the patch, followed by normalization. That’s the pipeline of the whole idea.
Sound wave projection: 16 kHz raw audio clipped to 40 ms frames. Each frame contains 640 values. Those values are displayed linearly in the same embedding space as the text tokens. There is no feature domain and no conformer layers. The existing Rotary Position Embedding (RoPE) LLM manages the 1-D temporal sequence. The audio encoder in E2B and E4B used 12 conformer layers. All that is removed.
Importance: The integrated weight space means you’re no longer tuning frozen encoders. Downstream optimization with LoRA or full tuning updates vision, audio, and text processing in a single pass. Hugging Face Transformers and Unsloth already support this.
The encoderless design minimizes multimodal delay. The LLM core begins processing immediately. No coder should finish first.
Skills & Performance
The Google DeepMind team has not yet published the full benchmark results for the initial launch. The official release notes say that the 12B model runs close to MoE’s 26B model in standard benchmarks, with less than half the total memory.
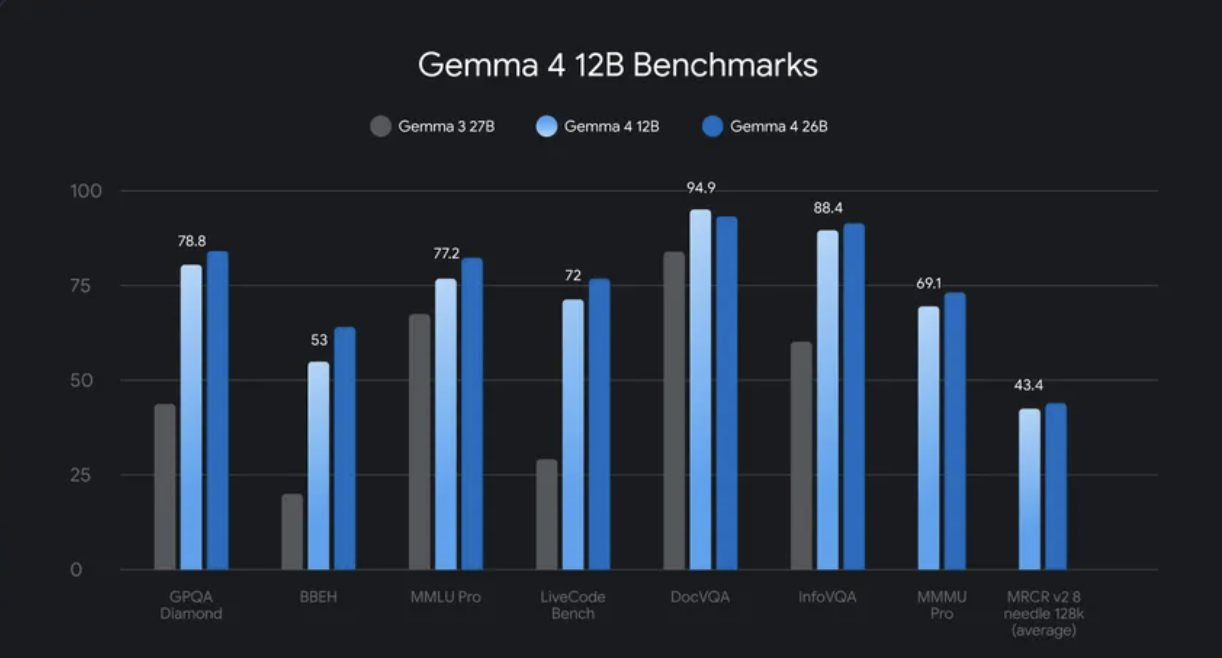
Demonstrated model skills include:
- Automatic speech recognition. It records audio natively without an external ASR pipeline.
- Agent thinking. It uses a multi-step workflow in place, with performance close to the 26B MoE model.
- Dialing. It separates the speakers according to the audio input.
- Understanding the video. Processes video frames alongside audio. The demo analyzed a 5-minute Google I/O segment using 313 frames at 1 FPS with a visual token budget of 70 per frame.
- Coding. Build an image processing application for Gradio using its code generator, which is provided locally with llama.cpp.
- Multimodal agent workflow. The official Gemma Skills repository at github.com/google-gemma/gemma-skills provides pre-built agent skills.
For Google’s Google AI Edge Eloquent app, switching to Gemma 4 12B produced what Google reports as a 60%+ jump in overall quality, with improved instruction tracking and scope adherence.
Marktechpost Visual Explainer
– AI research, model release and developer tools for 1M+ employees.
markettechpost.com
Key Takeaways
- Google DeepMind released Gemma 4 12B, a multimodal dense model with no coding under the Apache 2.0 license.
- View and audio feed directly into the LLM backbone — no separate optical (550M) or audio (300M) encoders.
- The 35M vision encoder uses a single matmul and factorized X/Y position lookup; raw audio projects 16 kHz independent directly.
- The first mid-range Gemma with native audio, and adds video, uses a 16 GB laptop.
- The benchmark performance is close to the 26B MoE model in less than half of the memory.
Check it out Model weights again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us