
Miso Labs released MisoTTS, an open-source 8-billion-parameter text-to-speech model. Produces expressive speech in both text and audio contexts. The model uses residual vector quantization (RVQ) to extend its sonic range. This avoids scaling a single flat vocabulary while keeping the parameter count constant.
What is MisoTTS
MisoTTS is an 8B parameter for the text-to-dialogue RVQ Transformer. It is inspired by the creation of Sesame CSM. It pairs a Llama 3.2-style core with a small audio decoder. Generates Mimi audio codes from text and optional audio content. Model conditions for both text and audio background. That second input allows it to respond to the speaker tone.
The text vocabulary is 128,256 tokens, and there are 32 audio codebooks. Mimi is a sound token, and the maximum sequence length is 2,048. Automatic thinking kicks in torch.bfloat16.
Miso Labs claims a latency of 110ms. It clocks ElevenLabs at 700ms and Sesame at 300ms.
Vocabulary size problem
Standard transformers generate from a fixed vocabulary of different tokens. That works when a small vocabulary covers the target area. Human speech does not match that thinking. It varies in tone, rhythm, emphasis, mood, and pronunciation.
Expanding the sound vocabulary is an obvious fix. But large names require more parameters in a conventional transformer. Each token must be represented and predicted by the model. Miso Labs calls this the vocabulary size problem.
The second problem is conditioning. Most TTS models are in text only form. Don’t pay attention to the tone of voice of the person speaking. Miso Labs argues that this contributes to the “mysterious valley” effect.
Residual Vector Quantization: The Core Idea
MisoTTS addresses both problems with residual vector quantization (RVQ). Miso Labs tracks RVQ in image generation research and Sesame’s CSM for sound. Instead of a single token index, the model outputs a vector of indices.
Each audio token has 32 codebook references in addition to 2048 codebooks. The model maintains a separate codebook for each location in the vector. To return the noise, it combines the observed vectors. Each codebook adds some enhancement to the signal.
This is what makes scaling work. The responsive vocabulary is proportional to the size of the codebook proposed in depth. Increasing the depth does not add parameters to the model. So MisoTTS reaches about 204832or about 10105 tokens can be dealt with. Miso Labs notes that indirect scaling would require a very large network.
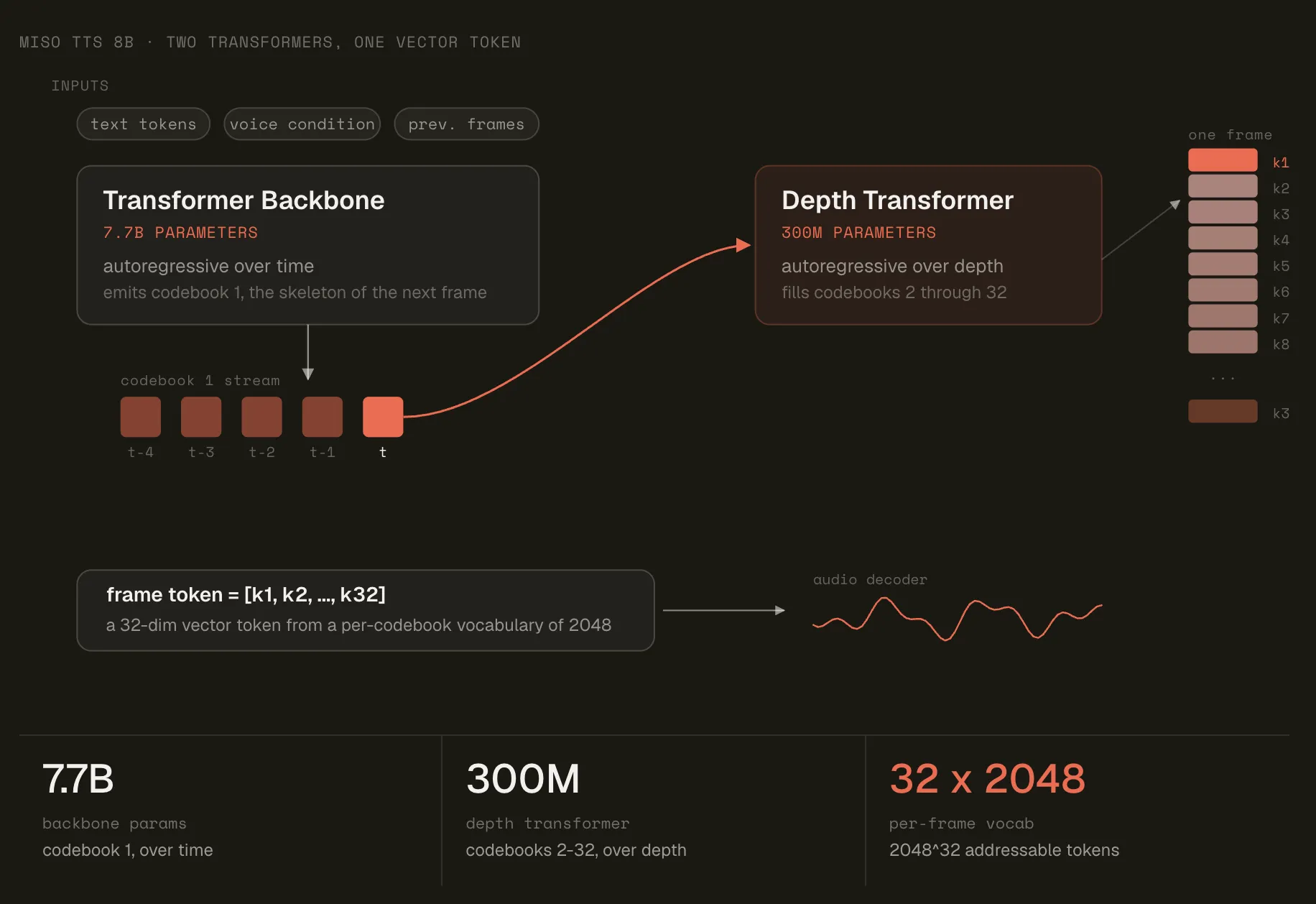
Two-Transformer Architecture
The model is divided into a core and a decoder. The core is a 7.7B-parameter transformer, autoregressive in time. It predicts the codebook’s initial index and hidden final state.
The 300M parameter decoder then works automatically over depth. It predicts the remaining codes of the codebook, one location at a time. The conditions for predicting each of the indices have already been selected in the framework. The same 300M parameters are reused in all locations.
Embedding follows the same logic. Text tokens use a single lookup. Audio token embedding is the sum of codebook observations for each position. The accompanying text and audio allows the backbone to use the history of the conversation. That’s how it moves the core to the muscles.
Strengths and Challenges
Power:
- Open weights on day one, under a modified MIT license.
- RVQ measures the sonic range without measuring the calculation parameter.
- Terms in audio context, not text alone.
- Local deployment keeps sensitive audio data in-house.
- Properties and calculations are listed in a public blog post.
Challenges:
- Half-duplex only, no turning yet.
- The larger model requires a capable CUDA GPU.
- API access has been announced but is not yet available.
- Latency and quality claims still require third-party testing.
Marktechpost Visual Explainer
Marktechpost · Model Briefly
01 / 09
Key Takeaways
- Miso Labs open-sources MisoTTS, an 8B text-to-speech model, under a modified MIT license.
- It works in both text and audio contexts, making generations respond to the speaker’s tone.
- Residual vector approximation (32 × 2048-way codebooks) measures words in ~2048³² without adding parameters.
- Architecture splits a 7.7B core (over time) and a 300M decoder (over-depth).
- It is half-duplex and single-turn only today; API access is pending.
Check it out Model weights, Repo again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us