
On June 3, 2026, Google introduced Gemma 4 12B Unified, an open source multimodal model designed to understand text, images, audio, and video within a single architecture. It includes a 256K window content with an efficient, laptop-friendly design intended for agent workflow and on-premises use.
The release also raises interesting questions about Google’s broader AI strategy, particularly the gap between models focused on public APIs and those made more widely available through open source tools. In this article, we’ll explore Gemma 4 12B Unified’s architecture, capabilities, and what its release means for developers.
What is Gemma 4 12B?
Gemma 4 12B Unified for Google DeepMind mid-size open source model in the Gemma family 4. Google describes it as a dense multimodal model designed to bring multimodal agent intelligence directly to laptops. It bridges the gap between the edge model Gemma 4 E4B and the main model Gemma 4 26B A4B Mixture-of-Experts.
The public model card lists Gemma 4 models in five sizes: E2B, E4B, 12B Unified, 26B A4B, and 31B. Gemma 4 12B Unified has 11.95B parameters, 48 layers, 1024 token sliding window focus, 256K content window, 262K vocabulary, and support for text, image, and audio input.
Main Features
Gemma 4 12B supports:
- Text construction and dialogue
- Long content memory is up to 256K tokens
- Coding, code completion, and code correction
- A function that calls an agent workflow
- Understanding video by processing video as frames
- Audio speech recognition and speech-to-text translation
- Multilingual support, with out-of-the-box support for 35+ languages and pre-training in over 140+ languages
Google also highlights automatic speech recognition, decoding, video understanding, coding, and agent reasoning in the Gemma 4 12B developer guide.
Why Google Needs a Centralized Integrated Model?
The original Gemma 4 family was released on March 31, 2026 with variants E2B, E4B, 31B, and 26B A4B. Google then released a draft of Gemma 4 MTP on April 16, 2026, followed by Gemma 4 12B Unified on June 3, 2026. This made 12B release a family tracking extension rather than the original Gemma 4 launch.
Extraction fills the functional supply gap. The E2B and E4B are designed for edge and mobile use cases, while the 26B A4B and 31B target workstations and high-end servers. The Gemma 4 12B is positioned as a laptop-friendly model that offers more powerful imaging and multimodal capabilities than edge models while using less memory than the larger 26B MoE model.
Key Changes From the Previous Gemma 4 Model
| Location | Previous Gemma 4 models | Gemma 4 12B Combined |
| Model size | E2B, E4B, 26B A4B, 31B in the beginning | Adds a dense 12B mid-sized option |
| Multimodal design | Some models use optical and audio encoders depending on the size | Projection without video and audio encoder in LLM |
| The sound | E2B and E4B had a traditional sound; 31B and 26B A4B do not list audio support | A mid-range Gemma 4 model with a traditional sound |
| Context | 128K for E2B/E4B, 256K for larger models | 256K |
| Purpose of use | Edge models for mobile, large models for workstations and servers | Laptop-first multimodal local agents |
| Fine tuning | Different encoders can add complexity | An integrated token loop can be tuned in one place |
| Measurements | E4B is light, 26B A4B is powerful | 12B sits among them on many legal points |
Overview of Properties
1. Integrated design without an encoder
The most important technical change in the Gemma 4 12B is its encoder-free multimodal design. Traditional multimodal models typically use separate encoders for visual and audio input before passing the representations to the language model. Google says the Gemma 4 12B does away with those separate multimodal encoders and projects raw image patches and audio waves directly onto the LLM embed. (blog.google)
2. Conceptual processing
For vision, the engineer’s guide states that the Gemma 4 12B replaces the multi-layer vision transducer used in other mid-size Gemma 4 models with a 35M parameter vision transducer. The 48×48 raw pixel plots are expressed in the LLM hidden dimension by one matrix multiplication, and the spatial information is attached by the factorized coordinate lookup matrix.
3. Sound processing
For audio, the Gemma 4 12B ditches the conformer-based audio encoder used in smaller variants of the Gemma 4. It cuts 16 kHz raw audio into 40 ms frames and sequentially runs those frames through the LLM input field.
4. Decoder and attention
The model card states that the Gemma 4 uses a hybrid attention mechanism that combines local sliding window attention with full global attention, with a final layer that remains global. It also uses integrated keys and values for global layers and Proportional RoPE for optimal performance on long content.
5. Low latency MTP drafts
Gemma 4 12B is “frame-ready,” meaning it supports Multi-Token Prediction drafts to be recorded by prediction. Google’s MTP documents explain that a small draft model predicts several future tokens, while the target model verifies them in parallel, improving the speed of decoding without changing the final guaranteed quality of the output.
Availability and Access
Gemma 4 12B is available as open weights in a variety of pre-trained and activated instructions via Hugging Face and Kaggle. Google’s launch post includes LM Studio, Ollama, Google AI Edge Gallery, Google AI Edge Eloquent, LiteRT-LM, Hugging Face Transformers, llama.cpp, MLX, SGlang, vLLM, and Unsloth as supported ecosystem methods.
Move hands: Start Gemma 4 12B with Ollama
- Download Ollama from
- Install it on your system and type ollama in the terminal to confirm the installation:
- In a new terminal window, paste
ollama run gemma4:12band press Enter
This will download gemma4 12b on your PC and you can connect to it directly
Hands on: Image Understanding
Let’s check out the Gemma4 12B to get a sense of the image this model is known for.
We will be using Ollama here but not in the terminal but in code
To use this enter i ollama python sdk:
!pip install ollama
import ollama
# Define the model ID
MODEL_ID = "gemma4:12b" # Ensure this matches your local Ollama model name
# Hands-on: Image Understanding
# Note: Google recommends placing image content before text in multimodal prompts.
# For local files, pass the path string. For URLs, download the image first.
image_messages = [
{
"role": "user",
"content": "Extract the key trends from this table.",
"images": ["financia_table.png"],
}
]
image_response = ollama.chat(model=MODEL_ID, messages=image_messages)
print(image_response["message"]["content"])Output:
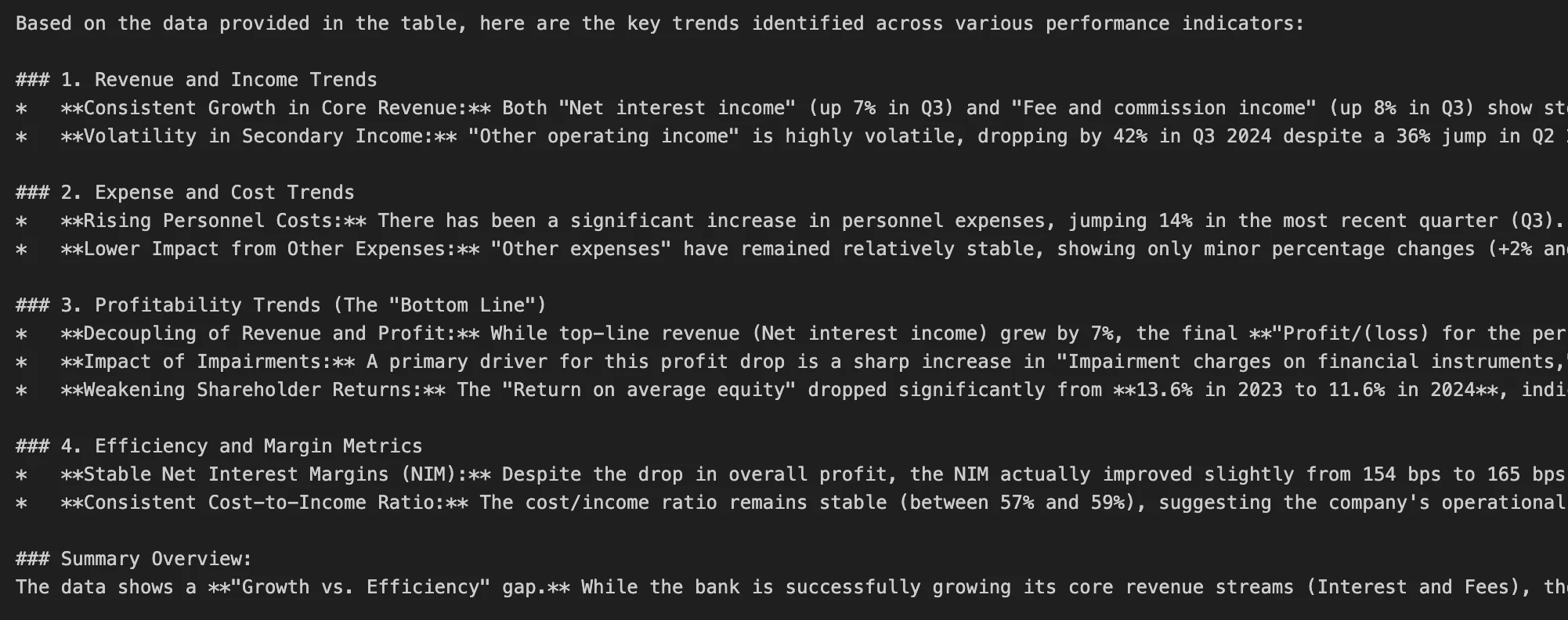
We can see the Gemma4 12B is able to analyze the image successfully. Google recommends placing image content before text with multimodal commands.
Benchmarks and Comparisons
The official card model reports the following benchmark results arranged in order:
| Benchmark | 431B data | Gemma 4 26B A4B | Gemma 4 12B Combined | Gemma 4 E4B | Gemma 4 E2B | Price 3 27B |
| MMLU Pro | 85.2% | 82.6% | 77.2% | 69.4% | 60.0% | 67.6% |
| AIME 2026, no tools | 89.2% | 88.3% | 77.5% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 | 80.0% | 77.1% | 72.0% | 52.0% | 44.0% | 29.1% |
| ELO codes | 2150 | 1718 | 1659 | 940 | 633 | 110 |
| GPQA Diamond | 84.3% | 82.3% | 78.8% | 58.6% | 43.4% | 42.4% |
| MMMU Pro | 76.9% | 73.8% | 69.1% | 52.6% | 44.2% | 49.7% |
| MATH-An idea | 85.6% | 82.4% | 79.7% | 59.5% | 52.4% | 46.0% |
| FLEURS, the lower the better | not available | not available | 0.069 | 0.08 | 0.09 | not available |
Gemma 4 12B sitting in the middle E4B and 26B A4B, which provide an efficient central environment for spatial thinking, coding, vision, and audio workloads.
The conclusion
The Gemma 4 12B isn’t just an incremental update; Google’s plan to bring powerful multimodal, agent-based AI directly to the devices of everyday developers. By moving text, image, and audio into a single, encoder-free decoder, we completely eliminate the complexity of local voice, encoding, and document workflows.
Ultimately, this model offers technology leaders a middle ground between thin models and cloud infrastructure. The smart play is clear: use it as a powerful on-premises model with open weights, ensure API availability before scaling, and tighten your deployments around measurable latency, security, and compliance requirements.
![]()
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than real people. I am interested in GenAI, NLP, and making machines intelligent (not to replace him yet). If he doesn’t use models well, he might be increasing his coffee intake. 🚀☕
Sign in to continue reading and enjoy content curated by experts.