 vs Agentic LLMs Explained")
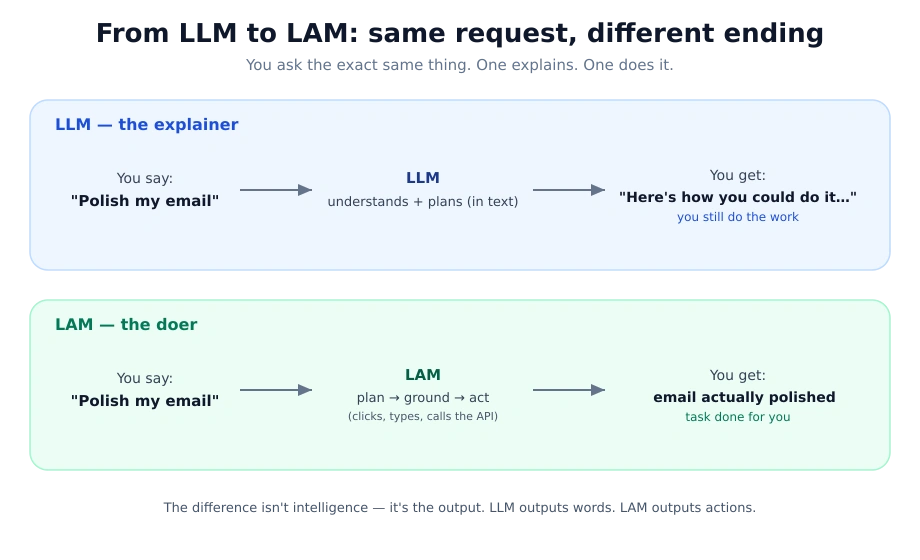
Tell your AI “Polish my email and send it.”
- A a chatbot gives you a section on how to do that.
- An Agent’s LLM opens your inbox and tries. Sometimes it works. Sometimes it clicks the wrong button three times.
- A The Great Action Model just do it, confirm it, and move on.
Same sentence, three results. A gap in the middle Large Action Models (LAMs) again agent LLMs it’s one of the most important distinctions in AI today, and it’s one of the least defined concepts.
In this article, we cut through the confusion with a simple breakdown of how each program is built, and a clear guide on when to use it.
What is an Agentic LLM?
An LLM like ChatGPT, Claude, or Gemini is a word predictor. It reads the context and generates the next token which is very useful. Its power comes from doing so on a large scale.
The LLM of the agent is a similar model placed within the tool consulting loop. It learns the goal, chooses the tool, learns the result, and then decides what to do next until the job is done or something fails. This loop is often called ReAct: the reason, action, be careful.
The important thing to understand is that the model itself has not changed. Remove the loop, tool definitions, prompts, and orchestration code, and return to the chatbot. The ability to take action resides in the scaffolding.
That makes refactoring powerful: the same model can write a copy, debug, or call an API without retraining. But honesty suffers. It can choose the wrong tool, establish parameters, or get stuck in loops. In production, these failures are not critical situations. Events at 2 AM.
Remove the loop and tools, and the agent’s LLM reverts back to being a chatbot. The “implementation” resides in the wrapper, not the model.
What is the Great Action Model?
LAM approaches the problem differently. Rather than taking a language model and forcing it to take action, you train the model to produce appropriate and actionable actions main purpose from day one.
The training data is different. A typical LLM is trained in web-scale text. LAM is trained on action trajectories: clicks, API calls, UI interactions, and multi-step completions. Salesforce’s AgentOhana pipeline is designed to aggregate this type of action data into a single training format. The model learns what a good action sequence looks like, not just a good sentence.
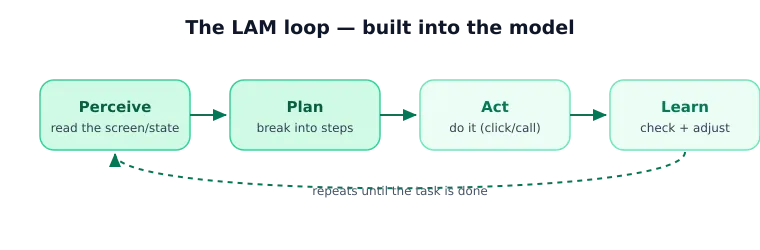
Architecture follows the same principle. Most LAMs use a see, plan, do, learn cycle: study nature, knock down the goal, take actionagain update the program. It is similar to the LLM loop of the agent, but the behavior is trained by the model rather than compiled by orchestration code.
Specialization produces remarkable efficiency. Salesforce’s xLAM-1B, a 1 billion parameter model nicknamed the “Little Giant,” outperforms the GPT-3.5 in call benchmarks while being about 175 times smaller. If the training goal is the same as the deployment, you don’t need a scale to win.
Aren’t They The Same Thing?
Good question, and the line is really blurring at the edges. An agent’s LLM with heavy work-intensive specialization can look a lot like a LAM. Some products use “LAM” as a marketing name for what is apparently GPT wrapped around a few tool definitions.

A noticeable difference lies in where the force of action begins:
| LLM for Agent | The Great Action Model | |
|---|---|---|
| The source of energy for action | Borrowed from scaffolding | Trained as a model |
| Remove the wrapper | Get a chatbot | He is still an action model |
| The point | Flexibility | Loyalty to defined tasks |
The most robust manufacturing systems in 2026 will not have to choose between the two. They will use the agent’s LLM to reason and interpret in an open manner, and then route advanced actions such as payments, data changes, or API calls through the supervised LAM.
Side-by-Side Comparison
| Size | LLM for Agent | The Great Action Model |
|---|---|---|
| Important outputs | Text (verbs extracted from it) | Formed verbs, native |
| Where the power of action resides | An orchestration wrapper | Model weights |
| Training data | Web scale text | Action trajectories + text |
| Standard model size | Large generalist (70B to 1T+) | Usually small and special (1B to 70B) |
| Power | Flexibility, imagination, open jobs | Reliability in limited action tasks |
| Common failure mode | Bad tool, arlucified args, infinite loop | Violates outside the defined action area |
| Real examples | GPT-4o + LangGraph, Claude + CrewAI | Salesforce xLAM, Rabbit R1, Adept ACT-1 |
Which One Should You Use?
The active question is whether the action field is open or closed. When system actions are constrained and known in advance, such as static APIs, UI workflows, or business processes, a LAM-style model is often more reliable, faster, and cheaper per operation.
If the job is open-ended, or you need a rich understanding of the language within the loop, an agent’s LLM gives you more flexibility.
Access the Agent’s LLM if:
- the job is open or poorly defined
- tool definitions are constantly changing
- you need strong thinking coupled with action
- you are doing prototyping and want speed of iteration
Access LAM if:
- the scene of the action is fixed and well defined
- wrong action has real consequences
- delay, cost, or delivery issue to the device
- you need predictable, readable output
Frequently Asked Questions
A. No. LAM is primarily trained to generate action using trajectory data, with different data formats, purposes, and optimization targets.
A. Yes. Many production agents use standard LLMs in orchestration. LAMs come in handy when reliability, cost, delays, or restricted shipments become an issue.
A. No. Some small LAMs perform better than large LLMs in action tasks, but LAMs can be large, such as the xLAM-70B.
A. Start with an agent’s LLM. The tools are older, iterations are faster, and the same agent building patterns still apply later.
A. No. Robust manufacturing systems often use both: LAMs for limited reliability and agent LLMs for extensive reasoning.
Sign in to continue reading and enjoy content curated by experts.