
The scaling of large-scale language models (LLMs) is increasingly constrained by the memory interface between High-Bandwidth Memory (HBM) and SRAM. In particular, the Key-Value (KV) cache scales with model size and context length, creating a significant bottleneck for long content interpretation. Google’s research team made a proposal TurboQuanta data-insensitive estimation framework designed to achieve very close distortion estimates for large-dimensional Euclidean vectors while dealing with both mean-squared error (MSE) and internal product distortion.
Addressing the Memory Wall with Data-Oblivious VQ
Vector quantization (VQ) in Euclidean space is a fundamental problem based on Shannon’s source coding theory.. Traditional VQ algorithms, such as Product Quantization (PQ), often require extensive offline pre-processing and data-dependent codebook training, making them unsuitable for the dynamic needs of real-time AI workloads such as KV cache management..
TurboQuant is a ‘data-oblivious’ algorithm and does not require specific data set tuning or calibration. It is designed to be more compatible with modern accelerators like GPUs by using vectorized operations instead of slow, uncomparable binary searches.
Geometric Mechanics of TurboQuant
The core method of TurboQuant involves using random rotation Π ERdxd in the input vectors. This rotation creates focus Beta distribution for each link, regardless of the original input data. At high dimensions, these correlations are nearly independent and uniformly distributed (iid).
This near independence simplifies the quantization design, allowing TurboQuant to solve the continuous 1D k-means / Max-Lloyd scalar quantization problem for each link. Optimal scalar quantizer for a given range b is obtained by minimizing the following MSE cost function:
$$mathcal{C}(f_{X},b):=min_{-1le c_{1}le c_{2}le…le c_{2^{b}}le1}sum_{i=1}^{2^{b}int_{frac{c_{i-1}+c_{i}}{2}}^{frac{c_{i}+c_{i+1}}{2}}|x-c_{i}|(2}cdot x f_{i}|^{2}cdot x f_{i+1})
By solving this configuration once with a suitable minimum range and saving the resulting codebooks, TurboQuant can successfully estimate vectors during online estimation..
Eliminating Internal Product Bias
A major challenge in quantization is that MSE-optimized maps often introduce biases when estimating inner products, which are important functions in transformer attention methods. For example, a 1-bit MSE-quantizer-optimal quantizer at high amplitude can exhibit a multiplicative bias of 2/π.
To fix this, Google Research has developed TURBOQUANTthe product, a two-stage approach:
- MSE platform: TURBOQUANT worksmse the quantizer uses a bit-width of b-1 to reduce the L2 normal of the residual vector.
- An unbiased platform: 1-bit function Quantized Johnson-Lindenstrauss (QJL) convert to the remainder vector.
This combination results in a smaller overall width b while providing an unbiased measure of internal products:
(mathbb{E}_{Q}[langle y,Q^{-1}(Q(x))rangle ]=angle y,xrangle )
Theoretical Performance and Durability
The research team established information-theoretic lower bounds using Shannon’s Lower Bound (SLB) and Yao’s minimum principle. TurboQuant’s MSE distortion is almost within a constant small factor (≈ 2.7) of the theoretical absolute limit for the entire bit width. With a narrow range of b=1, is a factor of about 1.45 from ideal.
| Bit width (b) | TURBOQUANTmse Distortion | Information-Theoretic Lower Bound |
| 1 | 0.36 | 0.25 |
| 2 | 0.117 | 0.0625 |
| 3 | 0.03 | 0.0156 |
| 4 | 0.009 | 0.0039 |
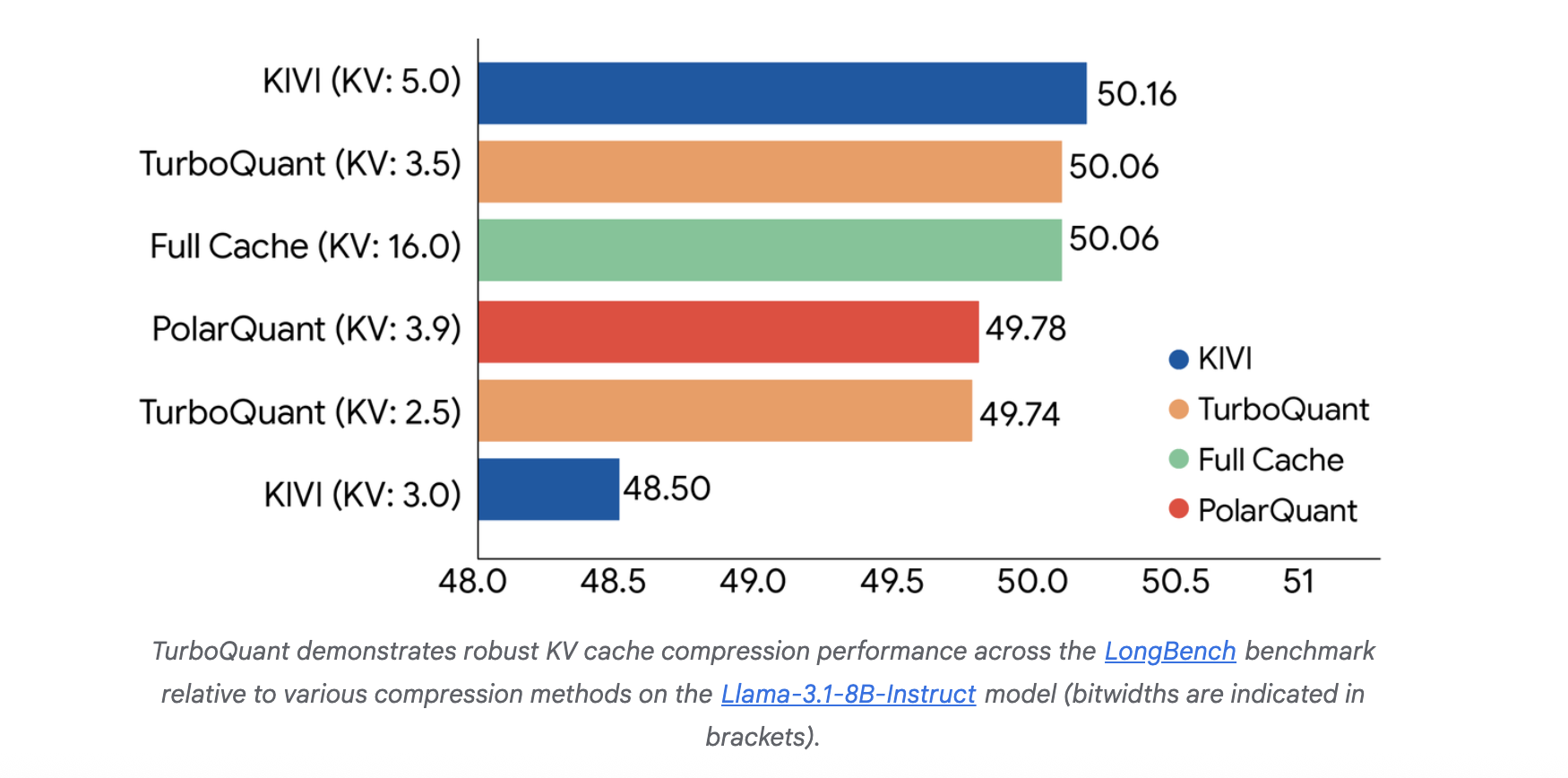
End-to-end benchmarks for LLM generation are implemented Llama-3.1-8B-Yala again Ministral-7B-YalaTurboQuant showed high quality retention. Under a 4x compression ratio, the model maintained 100% retrieval accuracy Needle-In-A-Haystack benchmark. In the Needle-In-A-Haystack benchmark, TurboQuant matched fully accurate performance up to 104k tokens under 4× compression.
With an incomplete bit width, the system uses an outlier treatment strategy, assigning high precision (eg, 3 bits) to some outlier channels and low precision (eg, 2 bits) to outliers, resulting in effective bits like 2.5 or 3.5 bits per channel..
Speed and Index Performance
For nearest neighbor search tasks, TurboQuant outperformed Product Quantization (PQ) and RabbitQ in recall while reducing indexing time to almost zero.. Because TurboQuant is data agnostic, it eliminates the need for the time-consuming k-means training phase required by PQ, which can take hundreds of seconds for large datasets..
| The way | d=200 Index | d=1536 Index | d=3072 Index |
| Product expansion | 37.04s | 239.75s | 494.42s |
| TurboQuant | 0.0007s | 0.0013s | 0.0021s |
TurboQuant represents a statistically-based transition to efficient, hardware-compatible vector optimization that bridges the gap between theoretical distortion limits and practical AI implementations..
Key Takeaways
- Zero Pre-Processing Required: Unlike Standard Product Quantization (PQ), TurboQuant is data-agnostic and runs quickly without requiring time-consuming k-means training on your specific dataset.
- Near-Theory Perfection: It achieves nearly equal distortion levels, remaining within a constant minimum factor 2.7 of the information-theory lower bound established by Shannon.
- Unbiased Internal Products: By using a two-stage method-using the MSE-optimal measurement followed by a 1-bit QJL conversion of the residuals-it provides unbiased internal product measurements, which is important for maintaining the accuracy of the transformer’s attention methods.
- Great Memory Savings: In the LLM implementation, compresses the KV cache with the end 5x. It achieves perfect quality neutrality at 3.5 bits per channel and maintains 100% recall in ‘needle-in-a-haystack’ tests up to 104k tokens.
- Quick Indexing for Searches: For vector databases, TurboQuant reduces indexing time to almost zero (e.g. 0.0013s for 1536-dimensional vectors) while being more efficient than conventional PQ in search recall.
Check it out Paper again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.