
Google has released Gemini 3.1 Flash Live in developer preview with the Gemini Live API in Google AI Studio. This model aims for lower latency, more natural, and reliable real-time voice interaction, serving as ‘Google’s highest quality audio and speech model to date.’ By processing multimodal streams in nature, the release provides a technical basis for building voice-first agents that go beyond the latency limitations of response-based LLM architectures.
Is the end of the ‘Wait-Time Stack‘?
The main problem with previous implementations of voice-AI was the ‘wait time stack’: Voice Task Acquisition (VAD) would wait for silence, then Write (STT), then Perform (LLM), then Synthesize (TTS). By the time the AI spoke, the human had moved on.
Gemini 3.1 Flash Live wraps this stack with native audio processing. The model doesn’t just ‘read’ the transcript; it processes acoustic nuances directly. According to Google’s internal metrics, the model is more effective in detecting height and speed than the previous Flash 2.5 native audio.
Even more impressive is its performance in ‘noisy’ real-world environments. In tests involving traffic noise or background chatter, the Flash Live 3.1 model picked up the right speech in ambient sounds with unprecedented accuracy. This is a significant win for developers building mobile assistants or customer service agents who work in the field rather than a quiet studio.
Multimodal Live API
For AI devs, the real change happens within the Multimodal Live API. This is the live, two-way streaming interface used WebSockets (WSS) to maintain continuous communication between the client and the model.
Unlike standard RESTful APIs that handle one request at a time, the Live API allows for a continuous stream of data. Here is a breakdown of the data pipeline technology:
- Audio input: The model expects green 16-bit PCM audio at 16kHzlittle-endian.
- Sound Output: It returns raw PCM audio data, effectively bypassing the delay of a separate text-to-speech step.
- Visuals: You can stream video frames as an individual JPEG or PNG photos in the amount of approx 1 frame per second (FPS).
- Protocol: A single server event can now host multiple content pieces at once—such as audio clips and their accompanying text. This makes client-side synchronization much easier.
The model also supports Enter by boatallowing users to interrupt the AI mid-sentence. Because the connection is bi-directional, the API can quickly set up the audio production buffer and process new incoming audio, simulating the sound of a human conversation.
Benchmarking Agetic Reasoning
Google’s AI research team doesn’t just optimize for speed; they are preparing for help. The release highlights the model’s performance in the ComplexFuncBench Audio. This benchmark measures the AI’s ability to perform multi-step scoring with various constraints based on audio input only.
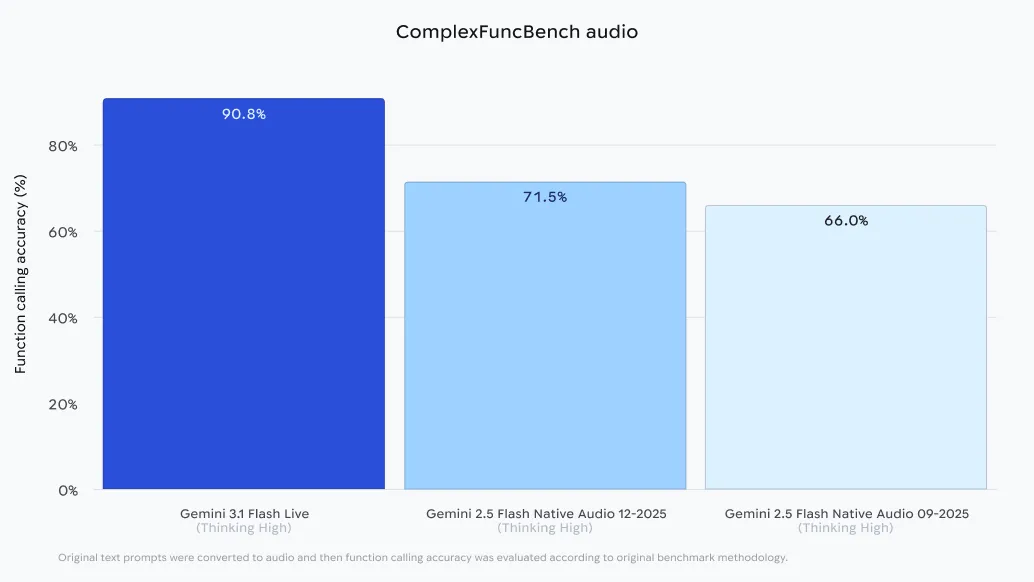
Gemini 3.1 Flash Live scored amazing 90.8% in this benchmark. For developers, this means that a voice agent can now perform complex logic—such as finding specific invoices and emailing them based on a price limit—without requiring a textual agent to think first.
| Benchmark | The result | The focal point |
| ComplexFuncBench Audio | 90.8% | A multi-step function calls from an audio input. |
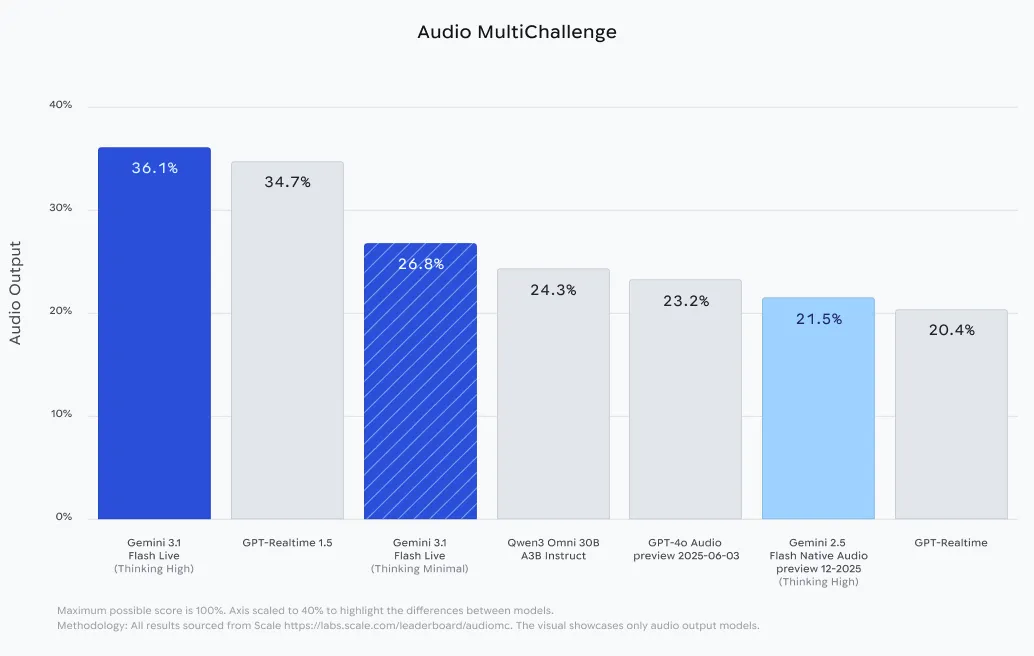
| Audio MultiChallenge | 36.1% | An instruction that follows in noisy/interrupted speech (thinking). |
| Content Window | 128k | Total tokens available in session memory and device definitions. |
Model performance in Audio MultiChallenge (36.1% when reasoning is enabled) also proves its durability. This benchmark tests the AI’s ability to stay focused and follow complex instructions despite distractions, languages, and background noise typical of real-world human speech.

Developer controls: thinkingLevel
A prominent feature for AI devs is the ability to tune the model’s deep thinking. Using the thinkingLevel parameter, developers can choose between small, low, medium, and high.
- Minimum: This defaults to live sessions, which have the lowest possible priority Time To Start Token (TTFT).
- Top: Although it increases latency, it allows the model to perform deep steps of “thinking” before responding, which is necessary for complex troubleshooting or debugging tasks delivered via live video.
Bridging the Knowledge Gap: Skills for the Game
As AI APIs evolve rapidly, keeping documentation up-to-date within a developer’s coding tools is a challenge. To address this, Google’s AI team maintains a google-gemini/gemini-skills a warehouse. This is a library of ‘skills’—selected context and scripts—that can be added to the AI coder’s knowledge to improve its performance.
The archive includes something gemini-live-api-dev a skill that focuses on the nuances of WebSocket sessions and hosting an audio/video blog. The extensive Gemini Skills database reports that adding the appropriate skill improves code generation accuracy 87% with Gemini 3 Flash again 96% with Gemini 3 Pro. Using these capabilities, developers can ensure that their coding agents are using current Live API best practices.
Key Takeaways
- Native Multimodal Architecture: It wraps the traditional ‘write-to-reason-combination’ stack into a single native audio-to-audio process, significantly reducing latency and allowing for more natural heights and speed detection.
- Bidirectional streaming: The model uses WebSockets (WSS) for full duplex communication, allowing ‘Barge-in’ (user interruption) and simultaneous transmission of audio, video frames, and transcripts.
- The Most Accurate Agentic Consultation: Optimized for triggering external instruments directly into the voice, achieving a score of 90.8% in ComplexFuncBench Audio for multi-step playback.
- ‘Thinking’ controls available: Developers can balance the speed of the conversation against the depth of thinking using the new
thinkingLevelparameter (from less to up) within the 128k token context window. - Preview Status and Constraints: Currently available in developer preview, the model requires 16-bit PCM audio (16kHz/24kHz output) and currently only supports sync workflow and partial content stacking.
Check it out Technical details, Repo again Documents. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.