
Most end-to-end OCR models slow down as the output increases. Each token generated adds to the KV cache. Memory increases and generation decreases. Parsing a bunch of pages doesn’t work. Baidu’s Unlimited OCR it says this directly. It replaces the decoder’s attention with a memory-consistent design.
The TL;DR
- OCR Unlimited is a 3B-parameter Mixture-of-Experts model, with only 500M active parameters.
- It replaces the decoder’s attention with Reference Sliding Window Attention (R-SWA), keeping the KV cache constant.
- The model splits a number of pages into one forward area under a maximum length of 32K.
- It scores 93.23 in OmniDocBench v1.5, beating the DeepSeek OCR benchmark by 6.22 points.
- Build on DeepSeek OCR by continuing to train, not running from scratch.
What is Unlimited OCR?
Unlimited OCR takes DeepSeek OCR as its foundation. It maintains DeepEncoder and Mixture-of-Experts decoder. The MoE design captures the full 3B parameters but only activates the 500M where it is considered.
DeepEncoder is a compression engine. Reduce SAM-ViT under window focus with CLIP-ViT under global focus. In the bridge, 16× token compression is used. A 1024×1024 PDF image becomes just 256 visible tokens. Fewer input tokens mean less prefill.
DeepEncoder natively supports five resolution modes, and Unlimited OCR supports two. The ‘basic’ mode works at 1024×1024 for multi-page work. The ‘Gundam’ mode uses a single page dynamic resolution.
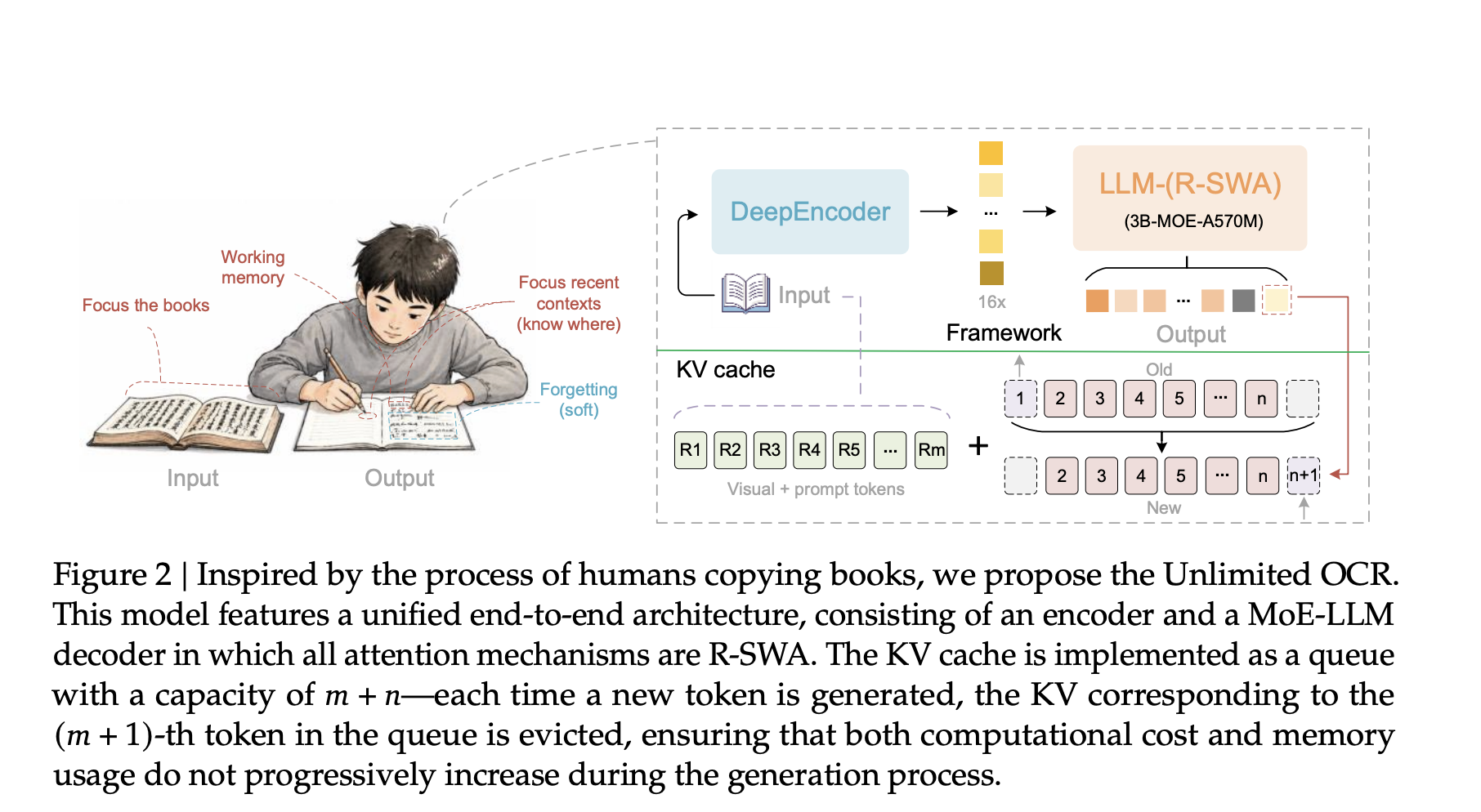
How SWA Keeps Cache Consistent
Contribution Attention to the Sliding Reference window. Common Multi-Head Attention stores the key and value of every token. As the output length of T increases, the cache also increases. Size is CNO(T) = Lm + T. Memory and latency increase without arrest.
RR-SWA breaks that link. Each generated token takes care of all reference tokens, meaning physical tokens and information. It also takes care of the previous n output tokens, where un changes to 128. Everything old is thrown away. The cache becomes a fixed array of size m + n.
Size is CR-SWA(T) = Lm + min(n, T) ≤ Lm + n. It is bound to be fixed. As T grows larger than n, the cache ratio tends to zero. So the memory is kept low and the latency of each step is kept low.
The research team compares this to soft forgetfulness. A copyist checks the source and the last few words. They do not reread everything that has been written so far. Virtual tokens are never updated. That avoids the progressive blur seen in linear focus. The functional simulator below allows you to change T and watch both caches respond.