Defeating the ‘Token Tax’: How Google Gemma 4, NVIDIA, and OpenClaw are Transforming Local Agent AI: From RTX Desktop to DGX Spark

Run the latest open Google omni models quickly on NVIDIA RTX AI PCs, from the NVIDIA Jetson Orin Nano, the GeForce RTX desktop to the new DGX Spark, to build your own AI assistants, which always work like OpenClaw without paying a huge “token tax” for every action.
The landscape of modern AI is changing rapidly. We are moving away from a complete reliance on large, traditional cloud models and entering an era of local, agency AI powered by platforms like OpenClaw. Whether it’s deploying a vision-enabled assistant on an edge device or building an always-on agent that automates coding workflows, the potential for generating AI on local hardware is virtually limitless.
However, developers face a persistent bottleneck and a huge hidden financial burden: the “Token Tax.” How do you get AI to consistently process multimodal input quickly and reliably without racking up astronomical cloud computing bills for every token it produces?
The answer to completely eliminating API costs is the new Google Gemma 4 family, and the ideal hardware platform of choice is NVIDIA GPUs.
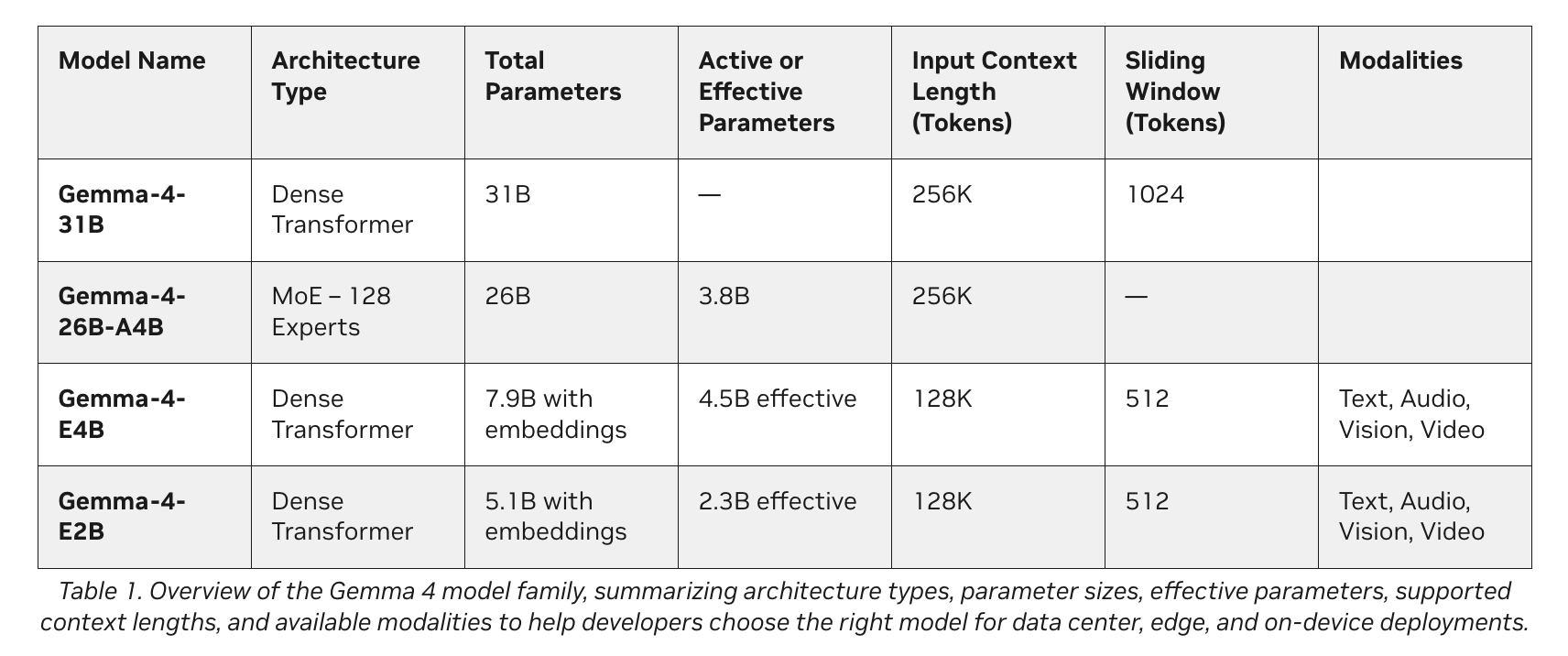
Google’s latest additions to the Gemma 4 family introduce a class of small, fast, and all-capable models expressly designed for optimal localization on a variety of devices. Developed in partnership with NVIDIA, these models easily scale from Jetson Orin Nano edge AI modules to GeForce RTX PCs, workstations, and DGX Spark personal AI supercomputers.
The Agentic AI Paradigm
Think of the Gemma 4 family as a high-performance engine for your local AI agents. Including the E2B, E4B, 26B, and 31B variants, these models are designed for efficient deployment anywhere. Naturally they support the use of structured tools (tasking) for agents and provide multimodal input that leaves each other, which means that developers can combine text and images in any order within a single prompt.
Depending on your hardware and purposes, developers generally use two main categories:
1. The most efficient Edge models (E2B and E4B)
- Tech: Gemma 4 E2B and E4B.
- How does this work: These models are designed for high performance, low edge measurement. They work completely offline with new-zero latency and zero API Fee.
- The best: IoT devices, robots, and local sensor networks.
- Hardware required: Devices include NVIDIA Jetson Orin Nano modules.
2. High Performance Agentic Models (26B and 31B)
- Tech: Gemma 4 26B and 31B.
- How does this work: This variant is specifically designed for high-performance thinking and developer-centric workflows.
- The best: Solving complex problems, code generation, and using agent AI.
- Hardware required: NVIDIA RTX GPUs, workstations, and DGX Spark systems.
Hardware Truth: Why NVIDIA Is Accelerating Gemma 4
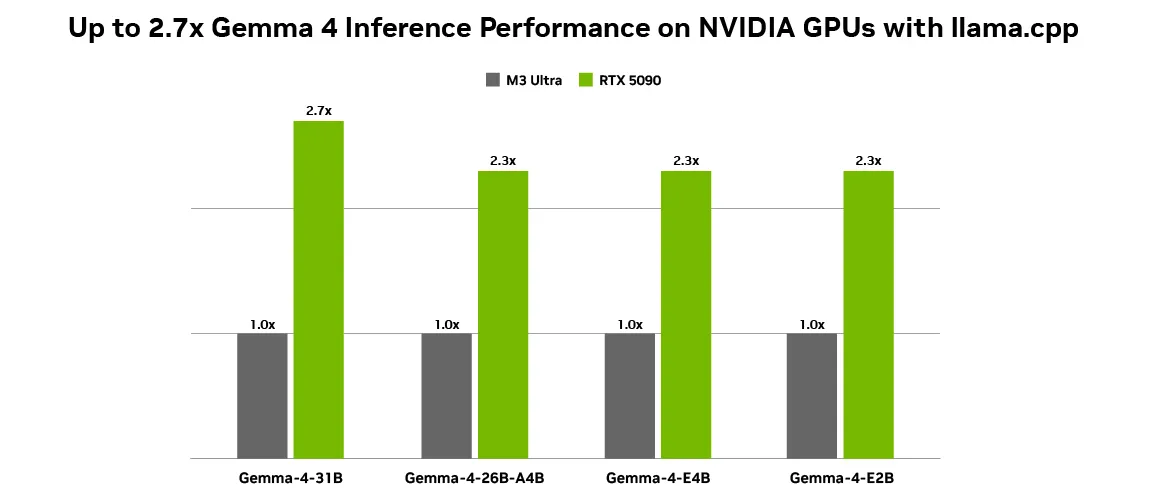
One of the most important aspects of making local AI financially viable is generating tokens. Using open models like the Gemma 4 family on NVIDIA GPUs achieves optimal performance because NVIDIA Tensor Cores accelerate AI workloads, delivering high performance and low latency. With up to 2.7x performance gains on the RTX 5090 compared to the M3 Ultra desktop using llama.cpp, localization is smoother than ever. This incredible speedup makes zero-cost local approximation work for heavy, persistent agent workloads.
OpenClaw & The “Token Tax” Solution
Why is the combination of Gemma 4 and NVIDIA winning the local AI race? It comes with speed and economy.
As local agent AI gains momentum, applications such as OpenClaw enable AI assistants to be always present on PCX PCs, workstations, and DGX Spark systems. The latest Gemma 4 models are fully compatible with OpenClaw, allowing users to create intelligent local agents that continuously draw content from personal files, applications, and workflows to automate everyday tasks.
For an always-on assistant like OpenClaw, running fast and local isn’t just a technical option; it is an economic necessity. If you were to use a cloud API to read every personal file, analyze screen context, and process thousands of automated actions per hour, the output of the “Token Tax” would be astronomical. Paying the cloud provider for each token generated by a back-end agent that runs continuously is not financially sustainable. By running Gemma 4 locally on an NVIDIA GPU, users eliminate these API token costs entirely. You get seamless, instant, instant, zero-latency indexing that makes always-on AI feel like a native, cost-free extension of your operating system.
Making it Safe: Meet NeMoClaw
While OpenClaw is a great personal AI app, business and privacy-conscious users need stricter restrictions. To make this setup secure, developers can use NVIDIA NeMoClaw. NeMoClaw is an open source stack that adds significant privacy and security controls to OpenClaw. With a single command, anyone can deploy automated agents that always work safely. Using the NVIDIA Agent Toolkit and OpenShell, NeMoClaw enforces policy-based monitoring rules, giving users complete control over how their agents handle sensitive data. This pairs well with on-premises Nemotron or Gemma models to keep data completely offline, avoiding both cloud data leakage and cloud API token costs.
Use Case 1: “Always On” Assistant Developer
- Goal: Run an always-on coding assistant that constantly monitors developer workflows to suggest code optimizations, debug errors in real-time, and automate developer workflows.
- Problem: Using cloud models for this creates a crippling token tax, as the assistant continues to read hundreds of lines of code every minute. Additionally, uploading proprietary codebase snippets to the cloud creates security and IP risks.
- Solution: Running Gemma 4 (31B variant) paired with OpenClaw locally on an NVIDIA GeForce RTX 5090 desktop.
- Result: The developer gets fast, zero-latency code generation and debugging. Because it runs locally, thousands of dollars in potential API token costs are completely eliminated, and proprietary code never leaves the workstation.
Use Case Study 2: Edge Vision Agent
- Goal: Install smart security cameras in a remote warehouse that can track inventory and identify hazards in real time using document and video intelligence.
- Problem: Streaming a 24/7 video feed in a cloud vision model is astronomically taxing and requires a lot of bandwidth. Standard local models are too large to fit on edge devices.
- Solution: Using the Gemma 4 E2B model on the NVIDIA Jetson Orin Nano edge AI module. The model uses its rich vision and video capabilities to process multimodal input seamlessly integrated into the device.
- Result: The system achieves high performance, low latency completely offline. It detects objects and analyzes video continuously 24/7 without generating a single cent in API token payments.
Use Case 3: Secure Financial Agent
- Goal: Create a personal assistant that automates tax preparation and updates sensitive bank documents in 35+ languages.
- Problem: Financial records cannot be exposed to cloud models due to strict privacy laws, and processing hundreds of pages of text generates a high token tax.
- Solution: A user uses NeMoClaw on NVIDIA DGX Spark to wrap an always-on agent with strict, policy-based monitoring. The agent uses the Gemma 4 26B model for its strong performance in complex problem-solving and reasoning tasks.
- Result: A highly secure, efficient agent that pulls the core of a person’s financial files securely. NeMoClaw ensures that the agent strictly adheres to privacy laws, keeps all banking data offline, is fast, secure, and has no cloud processing fees.
Ready to Get Started?
NVIDIA, Google, and the open source community have provided comprehensive tools to get you up and running and save on API costs quickly.
- For desktop users: NVIDIA has collaborated with Ollama and llama.cpp to provide the best local deployment experience. Download Ollama to run Gemma 4 natively, or install llama.cpp paired with the Gemma 4 GGUF Hugging Face demo.
- For Permanent Agents: Learn how to use OpenClaw for free on RTX GPUs and DGX Spark or by using the DGX Spark OpenClaw playbook.
Check out the Google DeepMind announcement blog and the NVIDIA tech blog for more details on how to get started with Gemma 4 on NVIDIA GPUs.
Note: Thanks to the NVIDIA AI team for the thought leadership/Resources for this article. The NVIDIA AI team supported this content/article for promotion.

Jean-marc is a successful AI business executive .He leads and accelerates the development of AI-powered solutions and started a computer vision company in 2006. He is a well-known speaker at AI conferences and has an MBA from Stanford.



