Liquid AI Releases LFM2.5-350M: A Compact 350M Parametric Model Trained on 28T Tokens with Trimmed Reinforcement Learning

In the current state of productive AI, ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, Liquid AI is challenging this convention with the release of LFM2.5-350M. This model is actually a technical case study in intelligence density with more pre-training (from 10T to 28T tokens) and massive reinforcement learning.
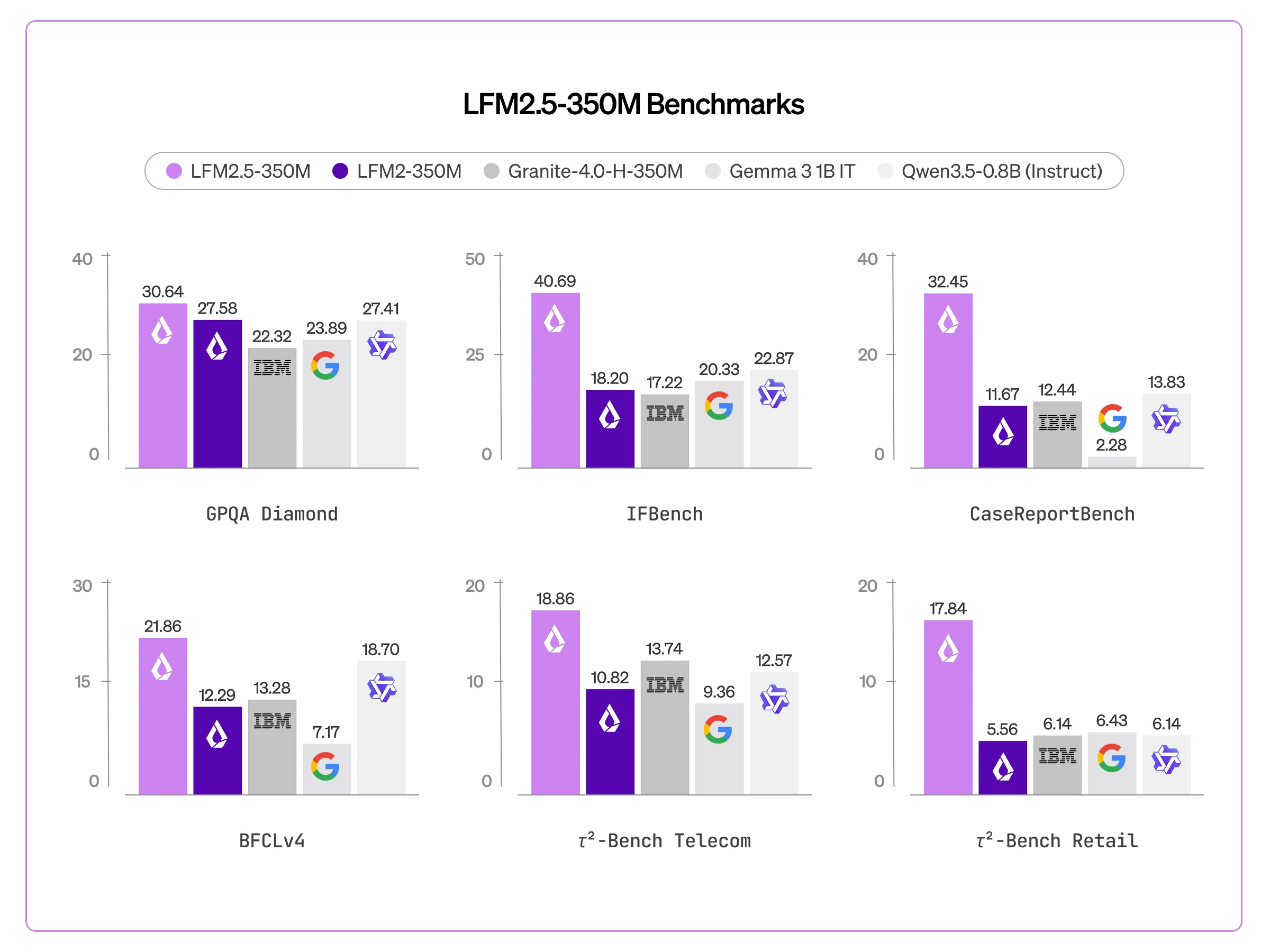
The importance of the LFM2.5-350M lies in its design and precision. While many AI companies have focused on frontier models, Liquid AI is looking at the ‘edge’—devices with limited memory and computation—by proving that a 350 million parameter model can pass. models more than double their size in several benchmarks tested.
Architecture: Hybrid LIV Backbone
The main technical difference of the LFM2.5-350M is its pure Transformer design. It uses a hybrid structure built into it Linear Input-Varying Systems (LIVs).
Traditional Transformers rely entirely on attentional methods, which have a quadratic scaling problem: as the context window grows, the memory and computational requirements of the Key-Value (KV) cache grow. Liquid AI addresses this by using a hybrid core that includes:
- 10 LIV Convolution Blocks with Double Gate: These handle most of the sequence processing. LIVs work in a similar way to Recurrent Neural Networks (RNNs) but are designed to be uniform and stable during training. They maintain non-volatile memory, reducing I/O further.
- 6 Grouped Query Attention (GQA) Blocks: By incorporating a small number of attention blocks, the model maintains high-precision retrieval and long-range context management without the memory overhead of a conventional Transformer.
This hybrid approach allows the LFM2.5-350M to support ia 32k content window (32,768 tokens) while keeping very soft memory.
Performance and Intellectual Density
The LFM2.5-350M was pre-trained 28 trillion tokens with a very high training-to-parameter ratio. This ensures that a limited number of model parameters are used to their maximum potential, resulting in a high ‘intelligence density’.
Ratings and Conditions of Use
The LFM2.5-350M is a special model designed for high-speed, agent operations rather than general-purpose thinking.
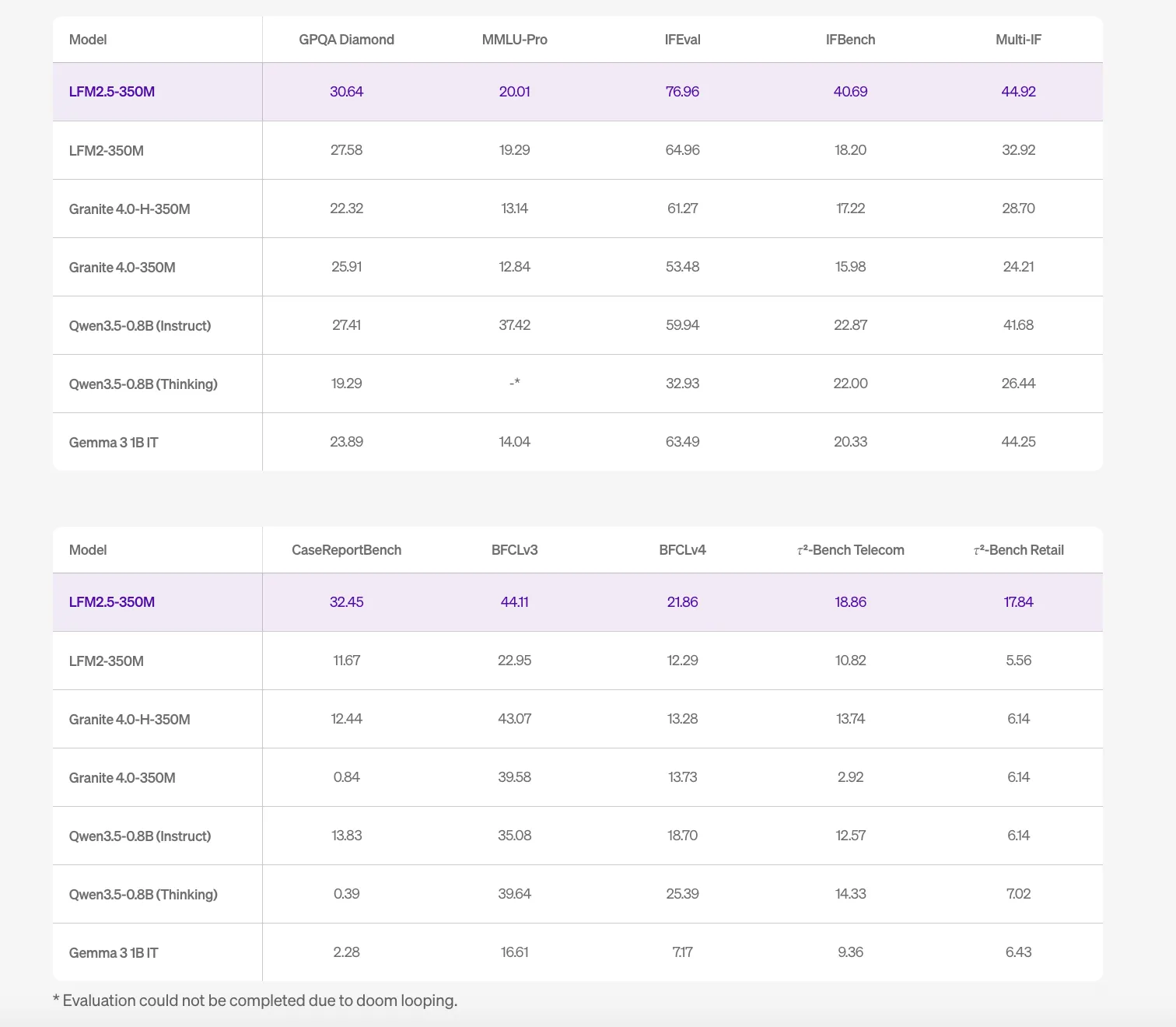
| Benchmark | The result |
| IFeval (Next Commands) | 76.96 |
| GPQA Diamond | 30.64 |
| MMLU-Pro | 20.01 |
The highest FEval scores show that the model works well for following complex, structured instructions, making it suitable for tool use, task calling, and structured data output (eg, JSON). However, the scriptures clearly state that The LFM2.5-350M is not recommended for math, complex coding, or creative writing. For those tasks, the computational power of large parameter calculations is always required.
Hardware optimization and Inference Efficiency
A major obstacle for AI devs is the ‘memory wall’—a bottleneck created to move data between the processor and memory. Because the LFM2.5-350M uses LIVs and GQA, it greatly reduces the size of the KV buffer, increasing the output. On one NVIDIA H100 GPU, the model can reach a result of 40.4K output tokens per second at a high rate.
The Liquid AI team reports results targeting a specific low-memory device that enables local usage:
- Snapdragon 8 Elite NPU: 169MB maximum memory using RunAnywhere Q4.
- Snapdragon GPU: 81MB maximum memory using RunAnywhere Q4.
- Raspberry Pi 5: 300MB using Cactus Engine int8.
Key Takeaways
- Extreme Intelligence Density: By training the 350M parameter model on 28 trillion tokensThe Liquid AI team achieved a very high 80,000:1 token-to-parameter ratio, allowing it to outperform models twice its size in several benchmarks.
- Hybrid LIV Architecture: The model is from pure Transformers through Linear Input-Varying Systems (LIVs) combined with a small amount Aggregate Question Attention (GQA) blocks, greatly reducing the memory overhead of the KV cache.
- Edge-First Performance: Designed for local deployment with 32k content window and significantly lower memory—as low as 81MB on mobile GPUs and 169MB to NPUs with special indexing engines.
- Special Functional Power: The model is highly optimized next command (IFEval: 76.96) and the use of tools, although it is clearly not recommended for complex coding, math, or creative writing.
- Main Performance: The efficiency of the architecture makes it a high-speed service, processed up to 40.4K output tokens per second on a single H100, making it ideal for high-volume data extraction and real-time segmentation.
Check it out Technical details again Model weight. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



