
The NVIDIA AI team has been released Cosmos 3. It is a family of omnimodal world models for body AI. Models include physical reasoning, world generation, and action. All three capabilities live within one open model. NVIDIA has open sourced benchmarks, training documentation, deployment tools, and datasets. I Cosmos 3 targeted rollout of robots, autonomous vehicles, and warehouse monitoring teams.
NVIDIA Cosmos 3
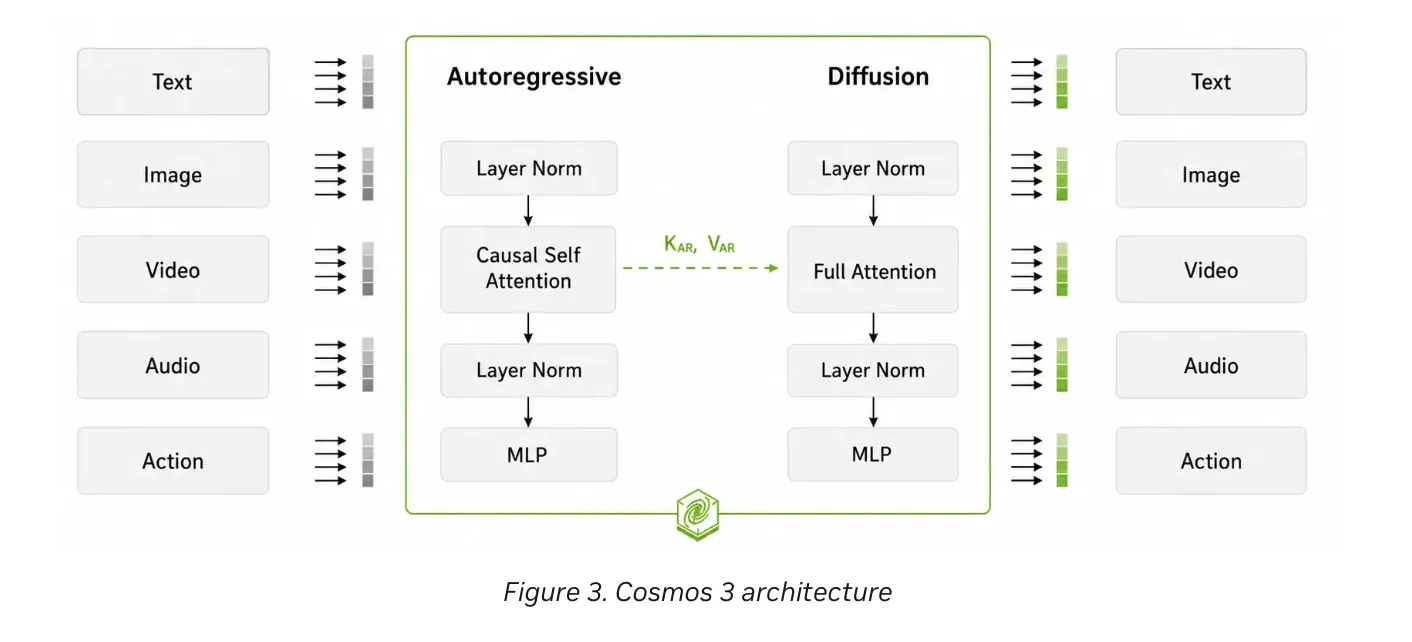
Virtual AI systems must understand the world before operating on it. Robots and cars need to see, predict, and act. Previous releases of Cosmos separated these functions into separate models. Cosmos 3 combines them with a Mixture-of-Transformers (MoT) design. The architecture is built around two towers.
The tower of the reasoner is a visual language model (VLM). It interprets images, videos, and text using an autoregressive architecture. It understands movement, object interaction, and other physical context. The NVIDIA team describes this tower as the brain of the model.
Generator tower generates future observations and action sequences. It uses a process based on video streaming and physics-aware actions. These results are placed in the context of the logic of the tower of reason. Information flows in one direction, from the thinker to the generator. A thinking person can run alone. The generator always operates both towers to generate a target.
So one model can handle thinking and acting together.
A Model Family
The NVIDIA team defines the scales of three models: Edge, Nano, and Super. Each uses a dual-tower Mixture-of-Transformers design. These two towers are initialized with pre-trained Qwen3-VL weights. That almost doubles the value of the core transformer parameter.
Cosmos3-Nano it is a 16B model built on top of an 8B compact transformer. Compatible with Qwen3-VL 8B architecture. Nano directs performance optimization to workstation GPUs. It runs on hardware like the NVIDIA RTX PRO 6000. That’s perfect for real-time robots and real-time AI on the device.
Cosmos3-Super is a 64B model built on top of a compact 32B converter. Compatible with Qwen3-VL 32B architecture. Super targets datacenter GPUs, including NVIDIA Hopper and Blackwell. It equates to large-scale artificial data generation and advanced thinking.
This release ships Nano and Super, as well as task-specific variants. These include Super Text2Image, Super Image2Video, and Nano-Policy-DROID.
How Integrated Design Works
Both towers share the same transformer structure and common attention operator. They use 3D multimodal rotary position embedding (mRoPE). mRoPE aligns video, audio, and action tokens along a single temporal axis. In the thinking mode, tokens pass through causal attention. This allows the prediction of the next token to see, plan, and think. In Generator mode, sound tokens are generated with full focus. Autoregressive tokens are not updated distribution tokens.
The model takes action as the main mechanism with dedicated action tokens. Supported inputs include text, image, video, and JSON action arrays. Output includes images, video, synchronized audio, action scenes, and text. A thinker follows the principles of Qwen3-VL-compatible message input.
Generation supports 256p, 480p, and 720p resolution tiers. Frame counts range from 5 to 300, default to 189. That equates to 7.9 seconds of video at 24 FPS. Audio is output as stereo AAC at 48 kHz. Action conditioning includes camera, vehicle, egocentric, single-arm, dual-arm, and humanoid embodiments. Each embodiment uses a fixed action dimension, such as 9D cameras.
The Benchmark Case
The NVIDIA team tested Cosmos 3 across all vision and generation suites. Conceptually, Super and Nano lead the VANTAGE-Bench in their categories. VANTAGE-Bench tests VLMs on real-world fixed-camera video. It includes warehousing, transportation, and smart facilities. Cosmos 3 also tops the Traffic Anomaly Reasoning (TAR) leaderboard. TAR is the official leaderboard for AI City Challenge 2026 Track 3.
In production, NVIDIA reports open-source results. Cosmos 3 is an open source SOTA on R-Bench. It also leads PAI-Bench, Physics-IQ, and RoboLab on public leaderboards. In Analytics, he leads two open source leaderboards. These include text-to-picture and picture-to-video without sound.
The NVIDIA team also introduced its Cosmos Human Exploration framework, called HUE. HUE breaks down each generated video into true yes/no questions. It gets four ratings in seven physical AI domains. Dimensions are semantic alignment, natural laws, geometric reasoning, and visual integrity. The VLM pipeline writes queries, and human experts refine them.
Marktechpost Visual Explainer
01 / 09
Key Takeaways
- Cosmos 3 is NVIDIA’s open family of omnimodal world models, combining physical reasoning, world generation, and action generation into a single model.
- A two-tower Mixture-of-Transformers design pairs an autoregressive VLM reasoner with a distribution generator, with a one-way transition from reasoner to generator.
- Two benchmarks now: Cosmos3-Nano (16B, dense core 8B) for workstations and Cosmos3-Super (64B, dense core 32B) for datacenters.
- NVIDIA has open sourced the benchmarks, six SDG datasets, training recipes, and the HUE benchmark under the OpenMDW-1.1 license.
- It reports open source SOTA on R-Bench and is leading Text-to-Image Processing Analysis and Image-to-Video Results.
Check it out Model weights, GitHub Repo, Project page again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? Connect with us